那些PPT里永远不会告诉你的破事儿
我入行那会儿——2017年——工业AI还是个金娃娃。大家挤在会议室里,对着大屏看数字孪生Demo,灯光调暗,就跟看科幻片似的。然后呢?然后就是三年漫长的POC周期。十几个项目,活下来的不到三成。不是技术不行,是人对AI那股子不切实际的期望把人害惨了。你让算法去预测设备故障,结果它把操作工的正常停机全给报了。车间主任拍桌子骂人,说你这玩意儿是“报警器还是催命符”?——真事儿。
说实话,工业场景和互联网那套完全是两个世界。数据脏得你怀疑人生。有一回,一个化工厂给了我们三年历史数据,同一个传感器位号变了四次,DCS系统里记录时间还时区错乱。我们花在洗数据上的功夫,比建模多五倍。💡 血的教训:搞工业AI,数据工程才是那个沉默的吞金兽。
问:工业AI到底能不能省钱?
答:能,但省的钱可能不够付你的咨询费。这话听着刺耳对吧?可这就是现实。我们团队给一家汽车零部件厂做视觉检测,用深度学习代替人工目检。上线第一个月,漏检率从3%降到0.5%,老板高兴坏了。可一算账……❌ 相机、光源、工控机、AI服务器、标注人力、算法调优,投了大概180万。而省下的质检员,两条线加起来才6个人,一年工资加福利也就50万出头。投资回报周期三年半。要不是冲着那家客户后续还有十几条线,这项目根本不会启动。
不过话说回来,你要是算上隐形成本——比如漏检导致的索赔、品牌损失——那可能早就回本了。但财务不会这么算。所以现在做工业AI,我们都逼着客户把质量成本模型先建起来。否则别碰。
问:那有没有低成本切入工业AI的办法?
答:从“烂活”干起,别老盯着预测性维护。预测性维护是工业AI的圣杯,也是最大的坑。数据量要求大,故障样本少得可怜,标注还困难。反倒是一些“烂活”——比如参数推荐、排产优化、能耗监控——更容易见效。举个实例:一个注塑车间,靠简单的回归模型推荐工艺参数,把调机时间缩短了40%。系统就部署在边缘计算盒子上,总成本不到五万。老板用了三个月,请我们团队吃了三顿火锅。这就是工业AI该有的样子:不炫技,只解决问题。
我还特烦那种一上来就提数字孪生、大模型的概念贩子。你做工业AI,连设备通信协议都没搞明白,就扯什么生成式AI?——省省吧。
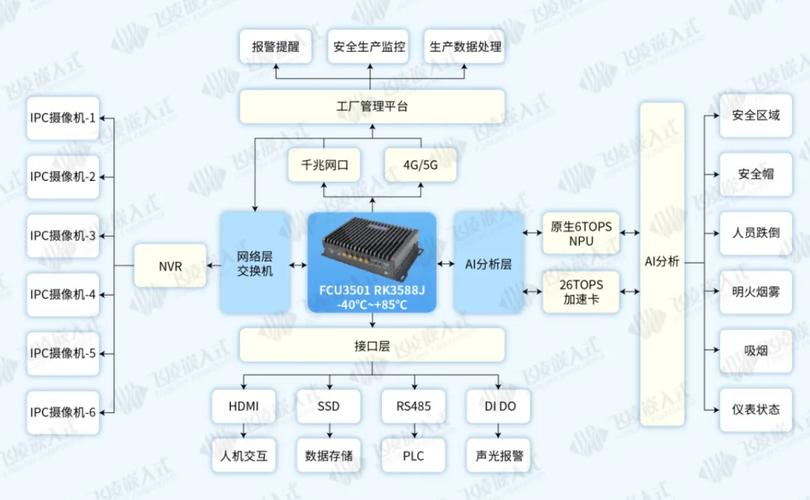
选型避坑:甲方爸爸们的三大幻觉

干了这些年,见了太多甲方被忽悠。总结三大幻觉:
- 幻觉一:有数据就能AI。数据不等于可用数据。很多工厂连数据字典都没有,MES系统里字段含义靠老师傅口口相传。这类项目,数据梳理起码三个月起步。
- 幻觉二:算法越复杂越好。其实工业里,逻辑回归加规则引擎往往比深度学习更健壮。我们一个刀具磨损预测,最后用的是朴素的统计过程控制(SPC),加上一点卡尔曼滤波,效果吊打LSTM。
- 幻觉三:AI可以完全无人化。别做梦了。工业AI现阶段就是辅助决策,尤其流程行业,安全约束太多。你让它直接控制阀门?线都给你搞跳闸。靠谱的做法是人机协同,AI给建议,人做确认。
所以啊,每次看到那些“无人工厂”的宣传片,我都在心里冷笑:拍完片子,灯光一撤,工人又都回来啦。
不过,也不是没有曙光。近两年,我明显感觉边缘AI和轻量化模型让落地难度降下来了。比如用TinyML做振动分析,一个几十块钱的MCU就能跑异常检测。成本下来了,客户才愿意试水。工业AI要爆发,靠的不是技术突破,是商业可行性的临界点。现在就在临界点附近晃荡。
最后说句掏心窝的话:工业AI这个赛道,真心不适合牛皮吹上天的人。它要求你懂工艺、懂数据、懂算法,更懂人心——知道车间主任怕什么,知道操作工烦什么。否则,你就等着在验收会上挨怼吧。❗