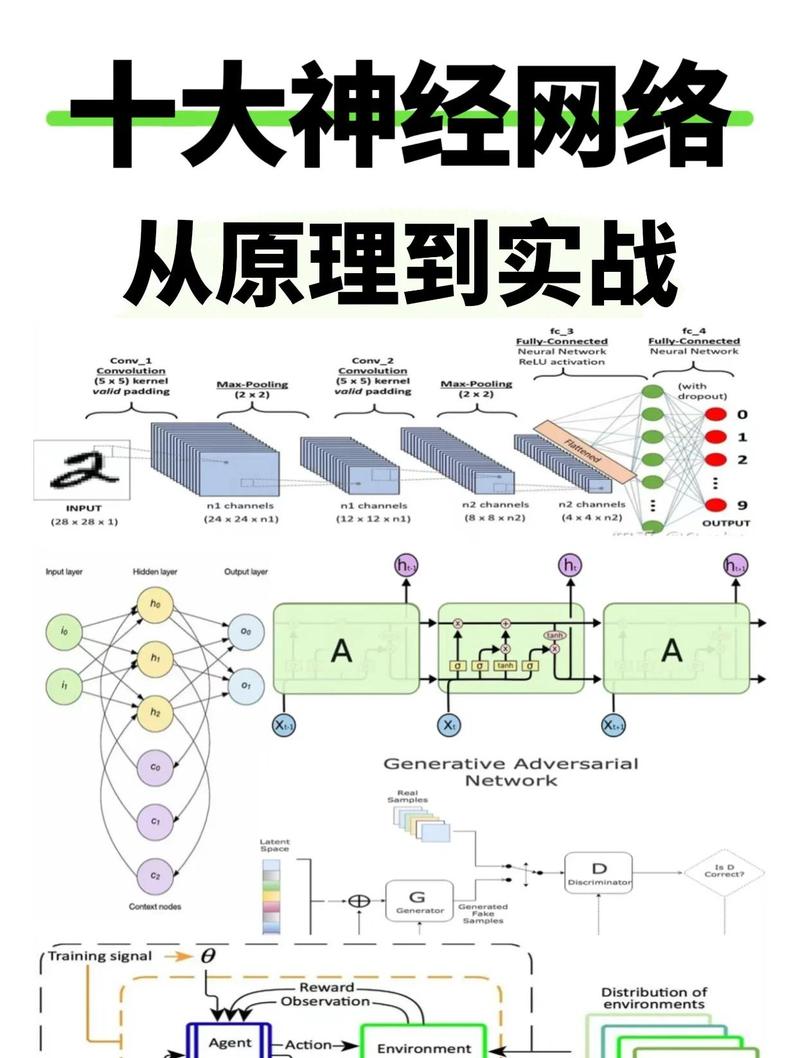
为什么深度学习在车间里总“水土不服”?
数据?先谈谈怎么把传感器信号变成训练样本
问:我们厂想用深度学习做刀具磨损预测,但采集的振动信号全是一维时序,怎么弄? 答:一维信号直接塞进 LSTM 或 TCN?可以,但往往效果稀烂。最好先做 时频变换——短时傅里叶变换(STFT)或小波变换,得到二维谱图,然后当图像喂给 CNN。我们试过,同一个型号的 CNC 铣床,单纯看振动 RMS 值根本抓不住断刀前的高频颤振,但一上 STFT 频谱,那些瞬态冲击特征就像黑夜里的灯一样明显。不过数据预处理最恶心的其实是 标签对齐。刀具磨损是渐进过程,你总得设个阈值判断“何时算失效”,这个阈值差一点点,模型学出来的东西就天差地别。我们一般结合加工表面粗糙度和电流增量综合定标。✅ 另一个血泪教训:别忽视了传感器的安装位置。有次我们采了三天的数据,结果发现加速度计没拧紧,信号里混进了设备本身的共振。模型倒是学得很认真,把那 50Hz 工频干扰当成了一个重要特征……后来每次调参前都得先检查一遍安装扭矩,真的,工业里细节就是魔鬼。
那些真正用起来的案例,到底做对了什么?
说点成功的例子吧。在半导体封装测试线上,焊线质量检测用深度学习,那真是降维打击。传统算法靠模板匹配,金线稍微变个角度就报错,虚焊跟真焊混成一团。换成 ResNet 加注意力机制,能够直接聚焦在键合点的形貌上。我们帮一家封装厂改了套系统,误报率从 12% 降到 0.3%,产线女工终于不用天天对着显微镜生气了。❗ 但难点在于——你必须自己花半年时间爬上百万张缺陷图,不是下载个 ImageNet 预训练模型就能搞定的。预训练权重在自然图像上有用,可到了 X 光或超声波图像上?有时候还不如随机初始化。 预测性维护是另一个战场。不过一说预测性维护,很多人上来就想搞 RUL(剩余使用寿命)预测,结果发现连故障的准确定义都搞不清。后来我们学乖了,先做 异常检测——给设备建个“正常状态”的分布边界,一旦偏离就报警。用自编码器或 GANomaly 都行,关键是训练时只喂正常数据。这里有个小窍门:特征提取别只依赖深度学习,从振动里算一些经典的时域统计量(峰峰值、峭度、裕度因子),和深度特征融合,鲁棒性会好很多。💡 问:小企业预算有限,连专职数据科学家的工资都开不起,能上深度学习项目吗? 答:能,但得换个思路。别想着从零搭一套端到端的系统,利用云平台上的 AutoML 工具箱——比如 Azure 的异常检测服务,或者国内一些低代码工业 AI 平台。它们把数据接入、特征工程、模型选择都封装好了,你只要上传振动文件,标出几段故障区间,它自动帮你训一个模型出来。我们试过某国产平台,三天的数据量,训出来的一个轴承故障分类模型,居然达到了 97% 的召回率,就是误报多了点,调了下阈值也能用。当然,这种方式的缺陷是你没法精细调优,遇到复杂工况可能抓瞎,但总比什么都不做强。小批量多品种?迁移学习或许是解药
工业制造最头疼的就是换产。昨天还生产 A 型号齿轮,今天切到 B 型号,模型立马变成瞎子。重新采集标注?一条产线停机一天损失几十万,老板能杀了你。这时候 迁移学习 的价值就出来了。我们做过一个实验:用大量 A 型号的缺陷图像预训练一个基础模型,然后只用很少的 B 型号样本(几十张)做微调,最终在 B 型号上准确率达到了 92%,而从头训练仅 65%。秘诀在于冻住浅层卷积核,只微调高层语义层——那些边缘、纹理的通用特征是可以跨型号复用的。但迁移失败的时候也很多,尤其当两种工件的材质或成像方式差异巨大时,强行迁移反而产生负迁移。这时候就得用域对抗网络(DANN)来拉近特征分布,不过实施复杂度陡然升高,没有经验丰富的团队慎入。 话说回来,我现在越来越少直接给客户推荐纯深度学习的方案了。很多时候,一个简单的手工特征加传统机器学习(比如 XGBoost)就能把事情办好,可解释性还强,工程师能看懂每个特征的含义。深度学习在工业里的角色,更像是一种“最后的手段”——当所有物理模型和统计方法都搞不定的时候,再把这头猛兽请出来。