去年在苏州,一家汽配厂的设备主管老周指着轰轰作响的冲压线,跟我说了句扎心的话:
“这套系统花了我三年时间调试,现在谁动一个参数我跟谁急——因为没人知道改了会发生什么。”
这不是保守。是恐惧。是智能制造大潮下,那些被PPT画得天花乱坠,落地时却让一线人员后背发凉的现实。而数字孪生(Digital Twin),恰恰是捅破这层窗户纸的那个手指头。
说实话,第一次听到“数字孪生”这个词,我还以为是某个咨询公司炮制的新概念泡沫。但!当我亲眼看见西门子安贝格工厂里,一个虚拟的机械臂在屏幕上精确到毫秒地模拟现实产线时……那种震撼,不亚于二十年前第一次摸到CNC。
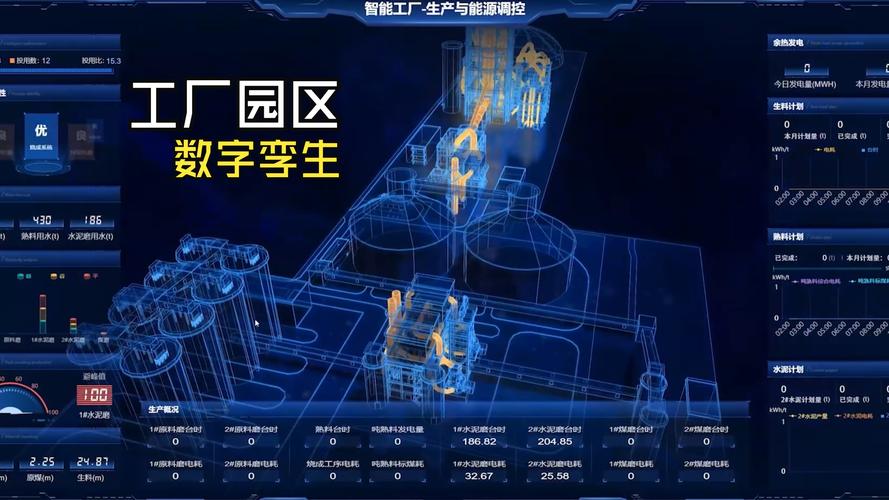
到底什么是数字孪生?别跟我扯那些虚的

简单粗暴:它就是在数字世界建一个和你物理资产一模一样的“克隆体”——实时同步、双向互动。不是仿真。仿真是一次性的,算完就完。数字孪生是“活”的,物理世界的传感器数据喂给它,它反过来控制物理世界。
举个例子。一台风机,有温度、振动、转速上千个测点。数字孪生模型在云端或边缘侧跑着。轴承温度突然异常?模型马上推演:“按这个趋势,三小时后可能抱轴。建议降速20%或者立即停机。” 更狠的,它能回溯历史:“上次出现相似模式是去年3月,当时是因为润滑脂污染,要不要查查油脂铁磁颗粒?” —— 这种预测性维护,没有孪生模型,靠老师傅听音儿?不是不行,只是老师傅越来越少了,对吧。
所以,它本质上是个试错沙盘。工艺调整、设备改造、排产逻辑,先在虚拟世界跑,跑通了再往产线上下发。老周那种恐惧,本质上是因为产线变成了黑箱。而数字孪生,是让黑箱透明化的那把钥匙。
“我们厂连MES都没上利索,搞数字孪生是不是太虚?”
这个问题我至少被问过二十次。我的回答往往是另一个问题:“你们设备OEE(整体设备效率)多少?”
—— “不到60%。”
—— “瓶颈在哪?”
—— “说不清,反正产能就是上不来。”
看,这就是症结。很多人以为数字孪生是给全自动化无人工厂准备的,那是误解!恰恰相反,越是问题多、变数大的老产线,越需要数字孪生来暴露问题、量化损失。与其花几百万上新设备,不如花小几十万先建一个局部孪生,比如只针对瓶颈工位或者关键动力设备。无锡一家做精密铸造的小厂,只在真空炉上做了数字孪生,把能耗曲线和模具寿命关联起来,一年省了37万电费。老板的原话:“原来我们是在烧钱,现在是在烧‘算过的’钱。”
💡 这里需要一个概念澄清。数字孪生不是非得搞个大而全的“全工厂虚拟同步”。它可以是组件级(如一个轴承)、设备级(如那台冲压机)、系统级(如整条涂装线)。起步完全可以小步快跑。
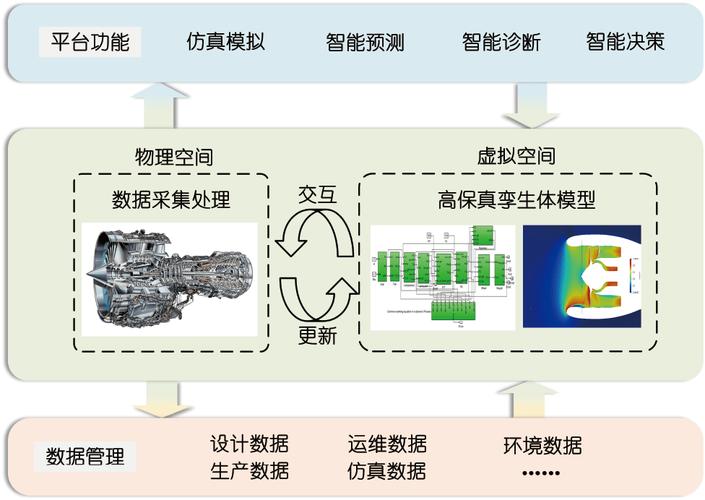
老将的恨:又来个吃数据的怪兽

不过话说回来,数字孪生被很多资深工程师嗤之以鼻,不是没道理。我见过最典型的抱怨:“数据都不准,建什么模?” 一针见血。数字孪生需要高质量、高频率的实时数据喂进去,而很多工厂——连一台机床的振动传感器都是坏的,或者采样率低到可悲,更别说各种协议不统一的设备怎么打通了。
这就逼着企业得先补工业物联网(IIoT)和边缘计算的课。否则模型就是“垃圾进,废物出”。曾有个项目,西门子Teamcenter和SAP系统之间,因为接口问题,BOM表(物料清单)竟然有两个版本,数字孪生同步出来发现装配干涉——不是设计错,是数据源没对齐。这锅谁背?
所以,智能制造不是买一个软件就万事大吉。数字孪生像个严苛的体检师,它会毫不留情地照出你数据治理的混。这是个让人又爱又恨的过程:恨它挑刺,爱它让你不必在半夜被叫醒去处理宕机。
问:数字孪生和传统模拟仿真到底有什么本质区别?我看很多软件演示差不多啊。
答:最大的区别在于“是否活着”。传统仿真是一次性的离线分析,输入假设条件,输出结果。而数字孪生是实时在线,与物理对象同步运行,不断根据最新数据修正模型。比如航空发动机,仿真可能分析某个工况下的应力,完事了;数字孪生则在整个飞行过程中持续接收传感器数据,动态评估剩余寿命,并提供操作建议。另外,数字孪生强调双向闭环——不仅能监测,还能反向控制,这在仿真里是没有的。
问:听说数字孪生对算力要求很高,中小企业用得起吗?
答:看你怎么用。如果非要建个全厂级厘米精度模型,那确实是个烧钱的无底洞。但中小企业完全可以聚焦高价值痛点。比如只针对一台关键数控机床建孪生,利用边缘计算在本地做实时分析,数据量不大,硬件成本可能就几千块。现在很多云平台(如PTC的Thingworx、阿里云的工业数字孪生)都提供按需租用模式,起步门槛已经比五年前低太多了。关键是你要先想清楚:到底想解决故障停机多?还是质量波动大?别想着一步登天。
绕过那些坑:从“看得见”到“算得准”

实话说,数字孪生项目失败,绝大多数不是技术问题,是认知问题。最常见的——把数字孪生当成3D可视化大屏。领导参观时确实酷炫,各种图表闪动,但运行半年后,没人再看第二眼。为什么?因为除了“看”,它啥也没干。没有分析模型,没有决策建议,没有控制闭环。充其量是个电子沙盘。
真正有价值的数字孪生,应该嵌入决策流程。举个例子,当排产系统要插单时,数字孪生立刻模拟:“如果现在插进这个紧急订单,A线瓶颈工序积压会增加40分钟,导致三个订单延迟。是否调整优先级或调用B线资源?” 它得能告诉你结果和风险,而不只是展示状态。
还有一个坑:数据所有权和安全性。当虚拟模型几乎一比一还原了你的产线,等于把所有工艺秘诀都数字化了——这些数据存在哪里?谁会访问?我曾经碰到一个案例,德国设备商提供给中方客户的数字孪生平台,模型细节只开放部分,核心算法藏在黑盒里,导致客户无法自主优化工艺。这提醒我们:搞数字孪生,数据主权和技术自主可控不能忽视。
说了这么多,你可能会觉得我像个布道者。其实不是。我只是看太多工厂花冤枉钱,买一堆传感器、上大屏,最后一地鸡毛。智能制造的口号喊得震天响,但落到车间里,就是设备能不能少停一次机,刀具能不能多用一个班次,新品换线能不能从三小时缩到半小时。数字孪生不是万能药,但它提供了一种最小成本的犯错方式。在虚拟世界翻车,总比在物理世界撞得头破血流要强——这道理,不需要什么工业4.0证书也能懂。