前段时间去一家轴承厂参观,车间主任老张指着一条产线跟我说:“这套设备上了机器学习模型,现在故障预警能提前三天,你信不信?”
我信。但我也见过太多“PPT上的智能工厂”——大屏幕花花绿绿,实际产线照样趴窝。
机器学习这几年在工业圈火得一塌糊涂。不过说实话,到底哪些落到了实处,哪些还是噱头?今天咱们就掰扯掰扯。
预测性维护:从“坏了再修”到“还没坏就知道”
传统工厂怎么维护设备?要么定期保养——不管设备状态如何,到点就换零件;要么等它罢工了再抢修。前一种浪费,后一种更浪费,停线损失动辄几十万。
机器学习切入的点很直接:让设备自己“说话”。振动传感器、温度探头、油液分析数据,这些信息喂给模型,它能学出什么样的信号组合意味着即将故障。比如轴承内圈磨损,初期振动频谱会出现特定频率的尖峰——人眼很难捕捉,但模型能。
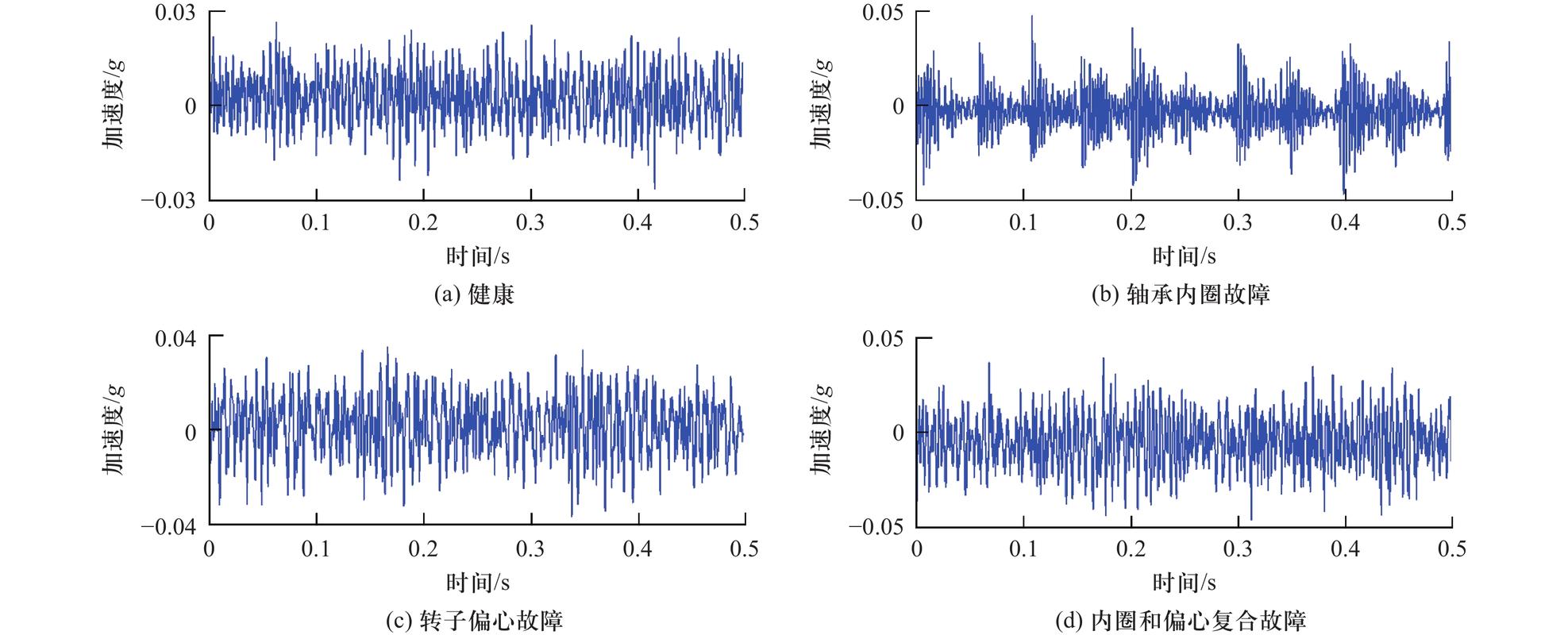
老张他们厂用的就是一套LSTM(长短期记忆网络)模型,吃掉了过去三年的设备运行数据和维修记录。现在系统一旦报警,维修班组提前介入,据说去年避免了四次非计划停机。不过也有坑:模型刚开始误报率高,操作工嫌烦,偷偷把警报关了——后来出了次小事故才老实。
这里有个细节,很少有人提:工业数据太“脏”了。传感器漂移、网络丢包、人工录入错误……不做数据清洗直接建模,效果能差到让你怀疑人生。我们团队曾经在一个纺织厂项目上,花了70%的时间在洗数据。
质量检测:机器视觉到底能不能替代老师傅的眼?
质检线上,老师傅瞳孔一缩,能看出0.1mm的划痕。这种靠十年经验积累的直觉,机器学习能学来吗?
能,但得换个思路。不是让模型去模仿人眼,而是给它不一样的“眼睛”。
比如一个做汽车活塞的产线,我们用结构光3D相机加卷积神经网络(CNN),检测毛刺和铸造缺陷。灯光下肉眼难辨的微小凹坑,在点云数据里就是明摆着的异常。✅ 理想很丰满,现实却很骨感:模型上线头两周,疯狂误报。查了半天,原因竟然是——工人换了个批次的清洗液,导致工件表面反光特性变了。训练集里根本没这种样本。

后来我们在预处理环节加了光照补偿和域适应(Domain Adaptation),才算稳住。所以啊,那些吹嘘“AI质检准确率99.9%”的,不妨问问他:换批原料还能不能行?换台相机还能不能行?
工艺参数优化:黑箱模型的信任危机
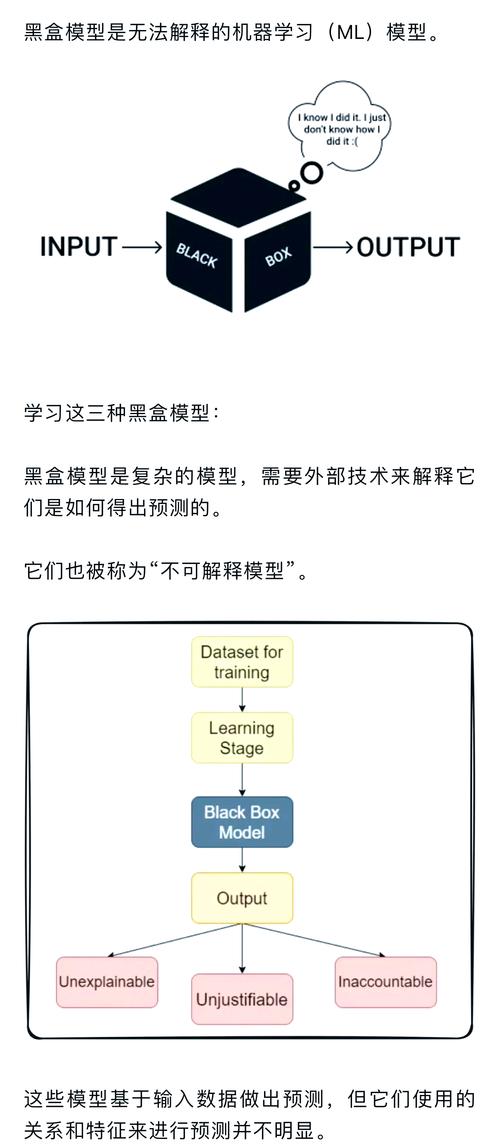
注塑、焊接、热处理……这些工艺的关键参数调优,以前全靠工艺师的试错。现在有了机器学习,扔一堆历史数据进去,它能给你找出一组最优参数组合。
但是,你敢直接上产线吗?
尤其是那些深度神经网络,整个儿一黑箱。工艺负责人最怕的就是:“你告诉我温度设153度最好,为什么?”答不上来,他就不敢签字。❗ 这就是工业界的现实:可解释性不是锦上添花,是安全红线和责任追溯的底线。
我们现在更多用高斯过程回归(GPR)或者规则提取技术,至少能给出个置信区间和影响因子排序。有次帮一家粉末冶金厂调烧结曲线,用了贝叶斯优化,把密度均匀性提升了1.2个百分点,同时模型还告诉工艺员:“温度变化率比最高温度本身更重要”——这让老工程师连连点头,因为和他的经验吻合了。💡
问:机器学习在工业落地最难的是什么?是算法吗?数据够多就行?
答:算法绝对不是最难的。现在开源框架一堆,GitHub上抄个代码就能跑个baseline。真正的拦路虎是“领域鸿沟”——懂机器学习的不懂工艺机理,懂工艺的不懂数据建模。还有数据基建:很多工厂连像样的数据采集系统都没有,传感器加装不全,历史数据躺在Excel里甚至纸质表格里。没有高质量数据,模型就是无米之炊。
问:对于中小企业,搞机器学习是不是太贵了?有没有低成本方案?
答:以前确实贵,但现在云服务普及了,算力成本降了很多。不过我认为最大的成本不是钱,是思维转变——领导是不是真的愿意投入懂数据的人,是不是接受试错。有个小招儿:可以从简单的规则学习(比如决策树)开始,用开箱即用的AutoML工具,先在一个痛点上做出效果,再慢慢铺开。千万别一上来就奔着“无人车间”去,那基本是烧钱。
问:预测性维护模型需要多久更新一次?是不是训练完就一劳永逸了?
答:绝对不可能一劳永逸!设备会老化,工况会漂移,原料批次不同都会改变特征分布。这叫概念漂移(Concept Drift)。我们建议至少按季度重新训练,或者设定性能监控指标,一旦准确率跌破阈值就触发更新。有的高精密场景,甚至用在线学习框架,模型随新数据实时调整。当然,这对数据管道和MLOps的要求又上了一个台阶。
机器学习在工业界,说到底不是一场技术秀,而是一块又一块硬骨头的啃噬过程。它让设备变的更聪明?或许是。但若没有扎实的工业知识做底,再炫的模型也不过是实验室里的玩具。老张最后跟我说了一句特实在的话:“别整那些虚的,能让我少停一次线,我就认它。”